Why mongodump is fast
TL;DR
Mongodump just read data from mongodb with raw bson, it doesn’t deserize/serialize data, and directly write these data into local filesystem.
More if you are curious about my discovery
With curiosity, I have written a mongo database Synchronizer which synchronize from one database to other database.
When I finish this, I try to benchmark it with mongodump/mongorestore pair. Surprisingly, mongodump is super faster than my hypothesis.
Benchmark
Scenario
A database with 4 collection, each collection have 1,000,000 document, every document is {"a": "b"}, no index for each collection.
The mongodb is deployed in my local machine.
Result
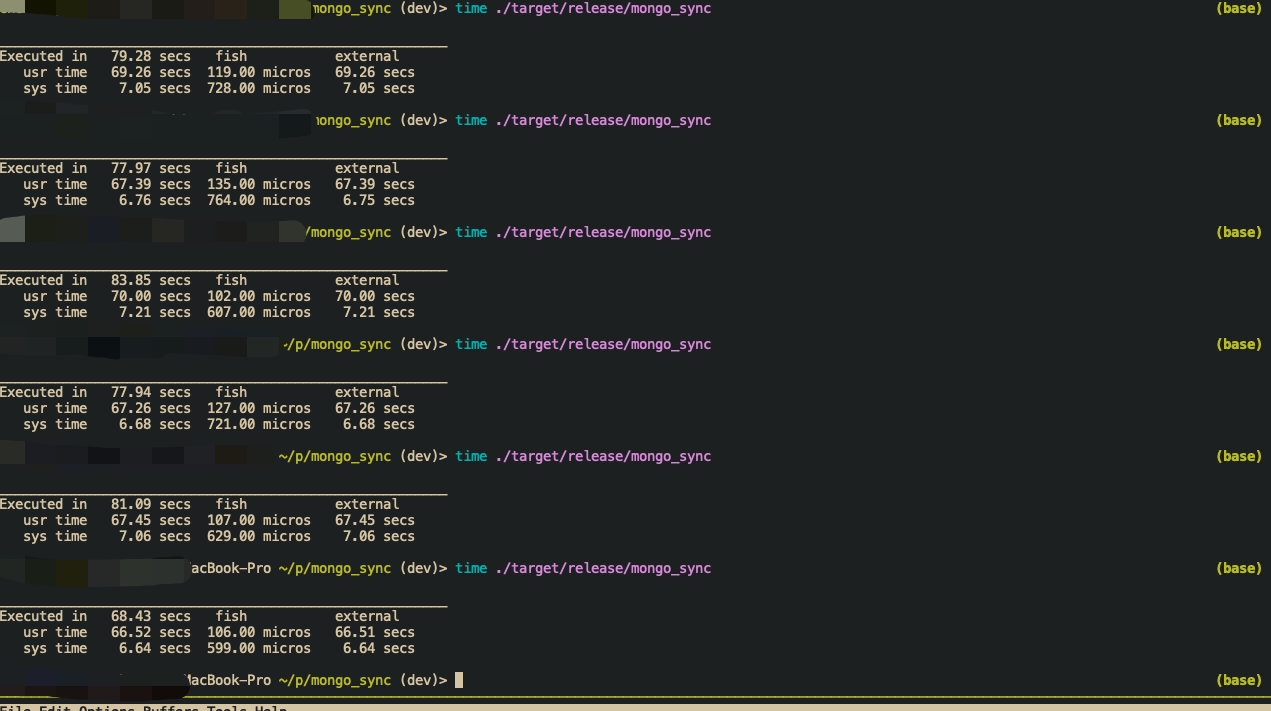
Here is my testing result:
MongoSync:
Relative configuration:
[src]
# source db url, need to be a replica set.
url = "mongodb://localhost/?authSource=admin"
[dst]
# target db url, don't need to be a replica set.
url = "mongodb://remote_address/?authSource=admin"
[sync]
# specify databases to sync
db = "bb"
collection_concurrent = 4
sync_buffer_size = 10000
Mongodump/MongoRestore:
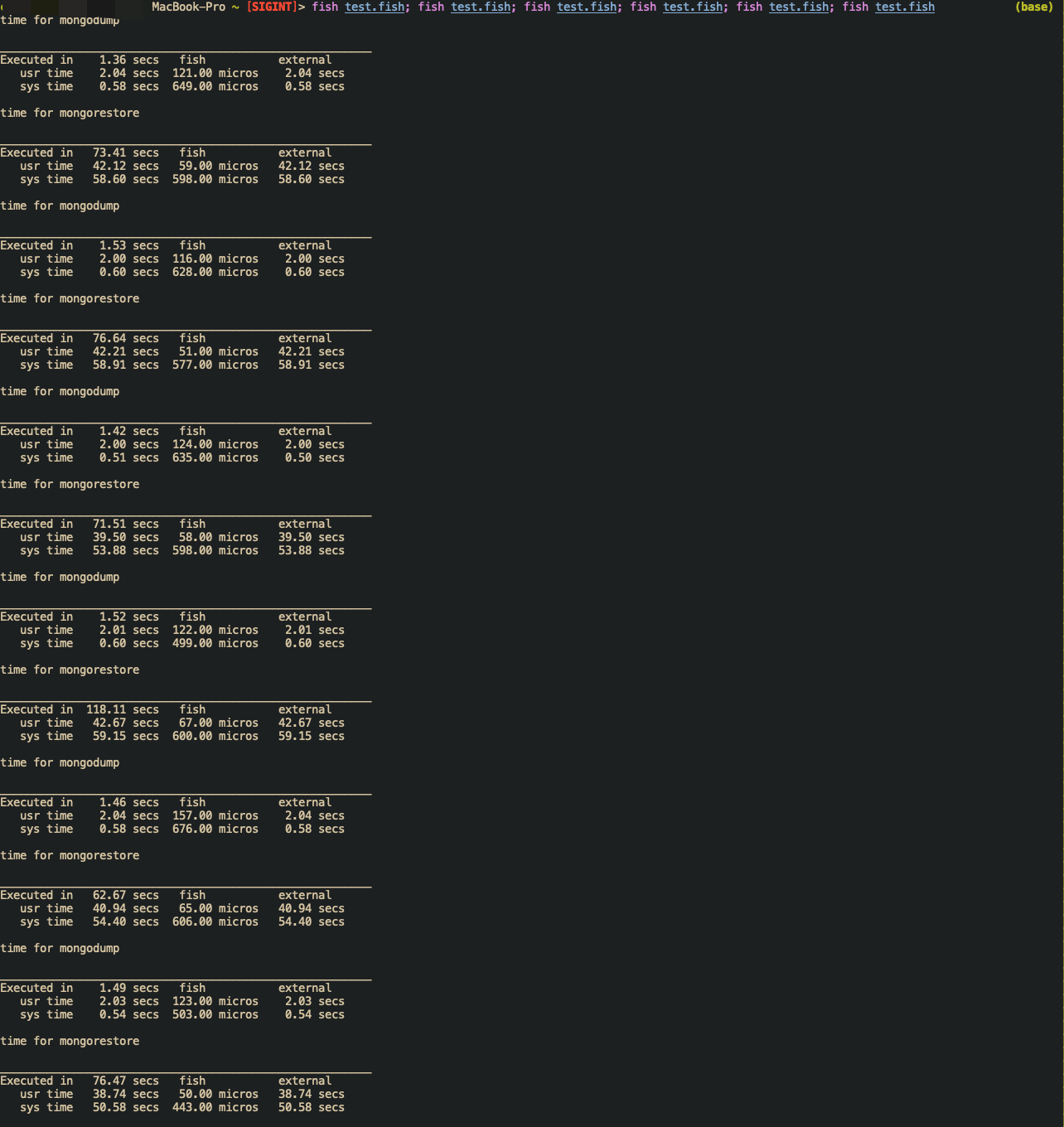
Relative fish script:
function run_dump_restore
echo "time for mongodump"
time mongodump -h localhost -d bb 1>/dev/null 2>/dev/null
echo "time for mongorestore"
time mongorestore -h remote_address --authenticationDatabase=admin --drop 1>/dev/null 2>/dev/null
end
run_dump_restore
Benchmark conclusion
- My implementation: takes about
78seconds. - Mongodump/Mongorestore: mongodump takes
1.46seconds to dump to local bson file, mongorestore takes79.8seconds to restore data to database.
It seems that my implementation is ok (some times even faster than mongodump/mongorestore), but here is one more problem: why mongodump so fast?
Basically, I think the progress to sync a database is:
- sync every collection inside a database.
- for each collection, just read one document one by one. Make these documents to a writing cache, flush cache into target collection. (we can use more threads in this step.)
It’s likely be implemented in rust like this (without error handling):
use rayon::ThreadPoolBuilder;
use crossbeam::channel;
use mongodb::sync::{Client, Collection};
fn main() {
let (sender, receiver) = channel::bounded(4);
// initialize database, and get collection_names to sync.
let source_db = Client::with_uri_str("mongodb://localhost/?authSource=admin").unwrap().database("bb");
let target_db = Client::with_uri_str("mongodb://remote_address/?authSource=admin").unwrap().database("bb");
let collection_names = source_db.list_collection_names(None).unwrap();
// create a threadpool to handle for specific collection's sync
let pool = ThreadPoolBuilder::new().num_threads(4).build().unwrap();
for name in collection_names.iter() {
let source_coll = source_db.collection(name);
let target_coll = target_db.collection(name);
let sender = sender.clone();
// spawn new thread to sync collection.
pool.spawn(move || {
sync_one_serial(source_coll, target_coll);
// notify that I'm done.
sender.send(()).unwrap();
})
}
let mut completed_count: usize = 0;
let total_count = collection_names.len();
while let Ok(_) = receiver.recv() {
completed_count += 1;
if completed_count == total_count {
// all sub tasks running to complete, and we are done.
break;
}
}
}
fn sync_one_serial(source_coll: Collection, target_coll: Collection) {
let buf_size = 10000;
let mut buffer = Vec::with_capacity(buf_size); // make a output buffer.
let cursor = source_coll.find(None, None).unwrap();
for doc in cursor {
buffer.push(doc.unwrap());
if buffer.len() == buf_size {
let mut data_to_write = Vec::with_capacity(buf_size);
std::mem::swap(&mut buffer, &mut data_to_write);
target_coll.insert_many(data_to_write, None).unwrap();
}
}
}
So mongodump should normally do the same progress, but write data to local file, why it’s so fast?
Why mongodump is fast
I’m trying to find what’s going on with mongodump, and get something like this, the source code is referred to here:
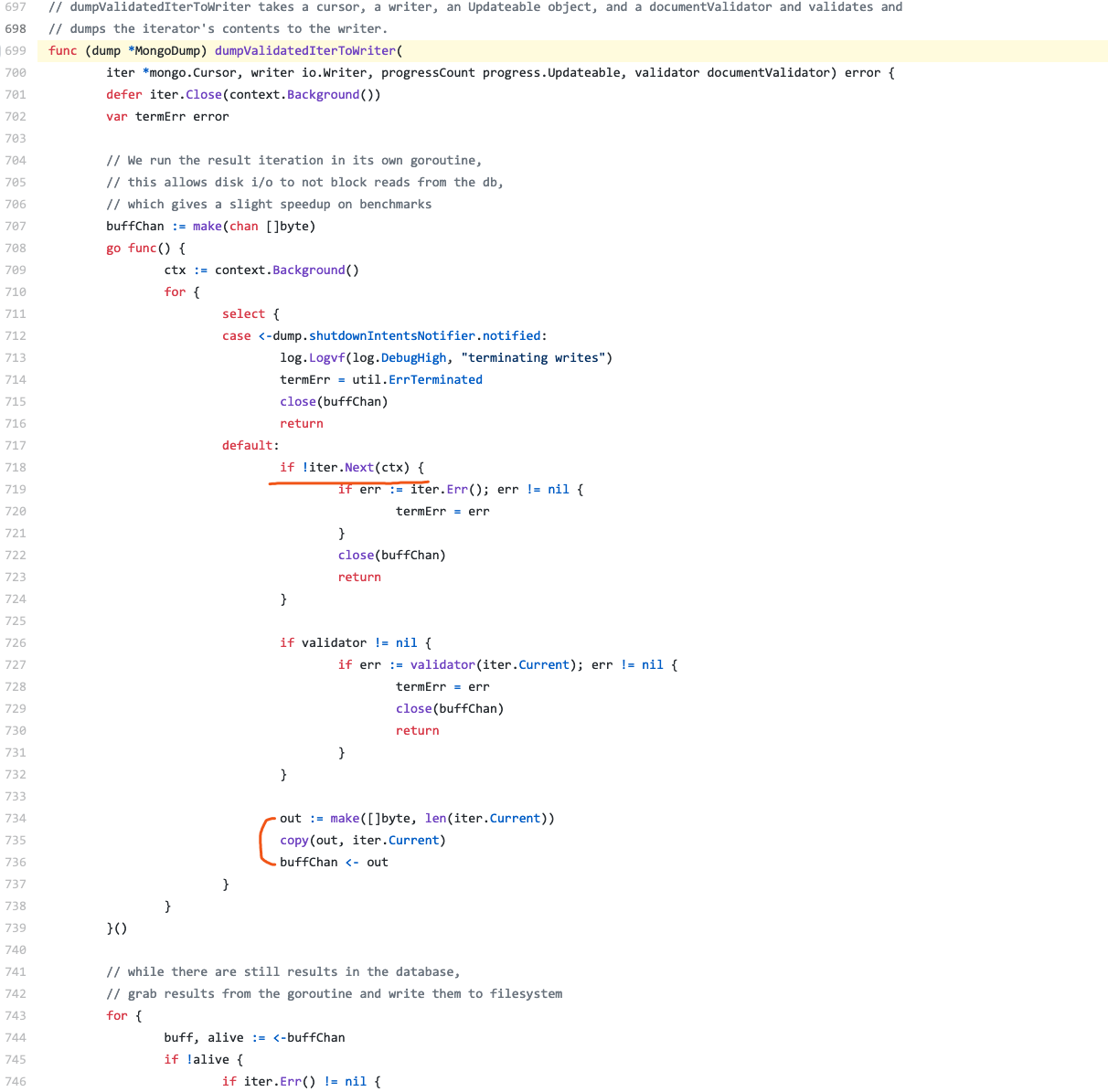
Hmm… It seems nothing special, mongodump is just iterating cursor, and copy the data to output buffer. Oh…wait, what’s the meaning of this?
out := make([]byte, len(iter.Current))
It seems that iter.Current just return bytes. Let’s go into the definition, Oh, it’s here:
type Cursor struct {
// Current contains the BSON bytes of the current change document. This property is only valid until the next call
// to Next or TryNext. If continued access is required, a copy must be made.
Current bson.Raw
bc batchCursor
batch *bsoncore.DocumentSequence
batchLength int
registry *bsoncodec.Registry
clientSession *session.Client
err error
}
The Cursor.Current is just bson.Raw, which is just bytes[].
So I think here is the reason, compared to my implementation(read document one by one):
when mongodump read data from source, it just get bson bytes, and don’t need to Deserialize bytes to document, then it just redirect these bytes to local storage, write bytes to local storage(SSD) is also fast.
In my scenario, it means that mongodump don’t need to Deserialize 4,000,000 documents, which can save a lot of time.
Conclusion
Nothing special :-)
More
Even mongodump/mongorestore handle bytes directly, why my implementation can sometime faster than mongodump/mongorestore?
Thanks to rust core feature(memory safety, fareless concurrency, no gc), which helps me to write a multi-threading based, mongodb synchronizer tool so easily.
Maybe I will make a post about how can I make this done :-)